Excuse Me, No! Plus a guide to generative AI video tools.
The best statement of the week is from Dr. Ngozi Okonjo Iweala, WTO Director-General: "Excuse me, NO!"

Excuse Me, No!
The weekend is upon us. My favorite moment of the week was this story. Thanks to my friend Femi Oke from Moderate The Panel for posting it and
Elise Labott for sharing it. Excuse me, No ! Watch Ngozi Okonjo-Iweala’s response when asked if globalization is dead. Yes, we should have a t-shirt!
The Rundown is building the back end and here’s a shot of what we are cooking. The scaffolding is going up… Paid subs are appreciated so we can work on getting this to product market fit. We take bitcoin…
Excuse Me, No!
Here’s a frank piece about the overhype of AI that The Rundown liked as very firm, and colorful, reality check on RAGs, and LLMs, and waste of time use cases. Good to check ourselves. This may well have been titled “Excuse me, No!”
The current approach does not scale in the way that we would hope, for myriad reasons. There isn't enough data on the planet, the architecture doesn't work the way we'd expect, the thing just stops getting smarter, context windows are a limiting factor forever, etc.
Your company does not need generative AI for the sake of it.
If you don't have a use case then having this sort of broad capability is not actually very useful. The only thing you should be doing is improving your operations and culture, and that will give you the ability to use AI if it ever becomes relevant.
Excuse Me, No!
I’ve been a fan of Perplexity.AI when it launched. I like going over there for daily wraps, and news I may have missed packaged up nicely, with sources. However, this concerned me and I have to raise a flag here. This is worth reading from Casey Newton over at Platformer.
Earlier this month, Forbes noticed that Perplexity had been stealing its journalism. The AI startup had taken a scoop about Eric Schmidt’s new drone project and repurposed it for its new “pages” product, which creates automated book-report style web pages based on user prompts. Perplexity had apparently decided to take Forbes’ reporting to show off what its plagiarism can do.
Here’s Randall Lane, Forbes’ chief content officer, in a blog post. “Not just summarizing (lots of people do that), but with eerily similar wording, some entirely lifted fragments — and even an illustration from one of Forbes’ previous stories on Schmidt,” noted “More egregiously, the post, which looked and read like a piece of journalism, didn’t mention Forbes at all, other than a line at the bottom of every few paragraphs that mentioned “sources,” and a very small icon that looked to be the “F” from the Forbeslogo – if you squinted.”
Perplexity then sent this knockoff story to its subscribers via a mobile push notification. It created an AI-generated podcast using the same (Forbes) reporting — without any credit to Forbes, and that became a YouTube video that outranks all Forbes content on this topic within Google search.
Any reporter who did what Perplexity did would be drummed out of the journalism business. But CEO Aravind Srinivas attributed the problem here to “rough edges” on a newly released product, and promised attribution would improve over time. “We agree with the feedback you've shared that it should be a lot easier to find the contributing sources and highlight them more prominently,” he wrote in an X post.
He continues: “But any notion that Perplexity’s problems stem from a simple misunderstanding was dashed this week when Wired published an investigation into how the company sources answers for users’ queries. In short, Wired found compelling evidence that Perplexity is ignoring the Robots Exclusion Protocol, which publishers and other websites use to grant or deny permissions to automated crawlers and scrapers.

Midjourney
AI Video
There’s been a tsunami of video Ai model announcements and promo’s in the past week, and it looks like the summer of super AI isn’t going to be confined to LLM’s. A couple months back OpenAI got a huge amount of attention with the promo of their AI video model, Sora— which at the time looked years ahead of anyone else in the AI video space. But after the past week, it seems OpenAi may find that by the time they release, their competitors may be way ahead of them.
There’s been so many different announcements. So here’s a comprehensive guide.
Google DeepMind
Google announced the progress they’ve made on their video-to-audio (V2A) technology that will let users “generate rich soundscapes” that will sync with videos, purely from a prompt. This tech is linkable with models like Veo to create sounds for a huge variety of footage, whether that be a “dramatic score, realistic sound effects or dialogue that matches the characters and tone of a video.”
Most video generation models can only generate silent output. Google is looking to solve this problem and take Ai-video to the next level by creating soundtracks to go along with these videos.
How does it work?
The V2A system starts by encoding video input into a compressed representation. Then, the diffusion model refines the audio from random noise.
This process is guided by the video input and language prompts users give to generate synchronised, realistic audio that closely aligns with the prompt.
Finally, the audio output is decoded, turned into an audio and combined with the video data.
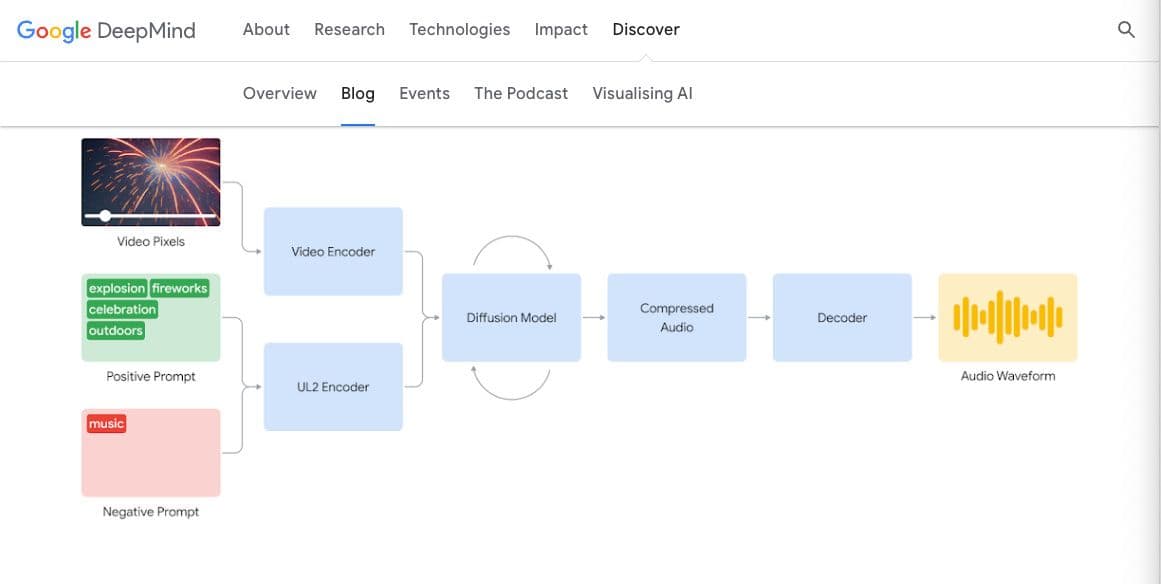
From Google’s training (still undisclosed what data was used to train), the tech learns to associate specific audio events with visual scenes, and actively responds to the info given. When it comes to refining the final output, users can use positive prompts to guide the AI closer to the sound they want. Or negative prompts to steer the AI away from unwanted sounds. This flexibility will be great for experimenting and playing around with getting the best sound possible for a video.
How good is it?
The sound quality is really impressive.
Prompt: Jellyfish pulsating under water, marine life, ocean
Prompt: Cars skidding, car engine throttling, angelic electronic music
Prompt: Wolf howling at the moon
Google does acknowledge that there are still a few limitations and are still in the research phase of addressing the issues:
Since the quality of the audio output is dependent on the quality of the video input, artifacts or distortions in the video, which are outside the model’s training distribution, can lead to a noticeable drop in audio quality.
They’re also working on lip syncing that will generate speech. We took a listen to a small preview and it definitely needs work.
Read more here https://deepmind.google/discover/blog/generating-audio-for-video/
Where and when can I get it:
Not ready yet, Google has only just shared their progress so far. For this, and to avoid early misuse they haven’t indicated when we’ll be able to access V2A.
Runway Gen 3 Alpha
Runway has been in the video AI space for a while. They just announced their new base model called Gen-3 Alpha, which they say “excels at generating expressive human characters with a wide range of actions, gestures and emotions … [and] was designed to interpret a wide range of styles and cinematic terminology [and enable] imaginative transitions and precise key-framing of elements in the scene.”
Cool factor:
This model is very refined, from the promo’s it looks like the attention to detail and quality of the video output means we can use very detailed prompts - a level of detail we haven’t been able to get on any tool so far.
Photorealistic humans - this model is especially good at generating expressive characters and you have more choice in the actions or emotions you want to convey in the video.
Style preference - They have a huge range of cinematographic styles and custom options for companies wanting more consistent and stylistically consistent video output.
How does it work?
From Runway’s blog
Trained jointly on videos and images, Gen-3 Alpha will power Runway's Text to Video, Image to Video and Text to Image tools, existing control modes such as Motion Brush, Advanced Camera Controls, Director Mode as well as upcoming tools for more fine-grained control over structure, style, and motion.
Fine grain detail: Gen-3 Alpha has been trained using highly descriptive, temporally dense captions, allowing for creative transitions and accurate key-framing of scene elements.
Runway worked in collab with a diverse team of artists and engineers to get the best quality possible and widest range of artistic style.
Prompt: Subtle reflections of a woman on the window of a train moving at hyper-speed in a Japanese city.
Prompt: FPV moving through a forest to an abandoned house to ocean waves.
There are limits - video output is closed at 10 seconds. Although, again we’re at the bottom of the ladder when it comes to this tech, this is the first of several models, each built on more improved infrastructure.
Where and when can I get it:
Very soon. Runway said “Gen-3 Alpha will be available for everyone over the coming days.”
They do have a form for organizations interested in Gen-3 Alpha to contact them directly.
Luma Ai Dream Machine
Luma AI, which was known for an app that let you take 3D photos with your iPhone, has now jumped into the generative video space. Last week they announced Dream Machine, a new text and image to video tool.
Check it out here.
There’s a huge range of styles to play around with. Here is one in an anime style:
And another in the style of Monsters Inc
You can watch their promo:
Where and when can I get it:
You can start using it today for free with your Google account. Hats off to them for now paywalling it. Although, while the free tier has great features, do keep in mind there are some limitations - as with most free versions of tools. Try it for free here https://lumalabs.ai/dream-machine
Kling by Kuaishou
This is a text and image to video tool that has blown away most other competitors we’ve seen and heard about so far. And has come out of nowhere. Kling was developed by Chinese tech giant Kuaishou, a competitor to TikTok. It’s being praised for the quality and length of the videos that can replicate real world physics, and how good it is at creating near perfect body and face reconstruction.
The output shows a more accurate depiction of what interaction with people and objects looks like. The understanding of real world physics is excellent. You can get really detailed here - even down to the facial expressions!
How does it work?
Like the others, we don’t know what this was trained on but Kling has very advanced 3D face and body reconstruction tech - everything looks very realistic and the limb movements look impressive for an output that is based on a single image. This means it doesn’t have the usual issues (like extra or bent limbs) we’ve seen with other tools.
You can create videos of up to two minutes at 1080p. This is way ahead of tools like Pika, or even Runway (when it comes to the time limit). It can also handle double what OpenAI claimed Sora could. The level of detail, motion quality, colours, sharpness, and rendering of the environments is all top notch.
Twitter user Angry Tom shared some examples:
Prompt: A Chinese man sits at a table and eats noodles with chopsticks
You can watch all their demo videos here:
Where and when can I get it:
Only available on the KWAI iOS app and you need a Chinese phone number to sign up.
Interested to learn more?
Sign up today to get notified on the future of communication and AI
More from the blog
Spotlight on Women in AI
Plus, our work on chatbot Wanja demonstrated quickly that the LLMs provided by Open AI are not up to scratch
Open AI's Own Goal and Women's Servitude in AI Voices. Plus, a summer of super AI from Google and Microsoft
Each week, we bring you Embedded. This will be our news and interview series. We are working on the 10-part podcast season in the rundown.
Our product update, and introducing Pressmate
We are building a press release tool for communications teams to buy time, stay on point and make messages.
A Landmark AI Report, CAIO Baby, and Adobe's Fuzzy Ethics
Both the overall number of investment events involving AI and the number of AI businesses that received money recently fell.