Build Google On Your Own Data. We Built Wanja.
Newsrooms and communications teams must consider creating their own search engines, which can be internally or externally facing. Start to understand what that means and how it works. The answer lies in RAG.

There’s been a buzzword in AI circles. RAG. Retrieval Augmented Generation. I would like you to get to know this term. I would also like you to understand this because I believe it will ultimately prove valuable and efficient in your work, not only in the field of communications.
When you use a large language model like Chat GPT, Bard, or Anthropic, those provide information that is:
- Frozen in time
- They lack specific domain data, like your company's or organization’s private data
- They’re expensive to produce
- They can hallucinate (offer an answer that seems credible but is wrong)
What is a RAG?
A RAG is a relatively cheap and accessible way of providing private data to serve your internal teams or external clients in an accurate, easy, and high-quality way. This article is one of the best explanations I have read about RAG. With nice, clear diagrams if you’re visual like me.
Retrieval augmented generation (RAG) is an architecture that provides the most relevant and contextually-important proprietary, private or dynamic data to your Generative AI application's large language model (LLM) when it is performing tasks to enhance its accuracy and performance. (Pinecone)
I became interested in understanding it because I can see the value in leveraging private, proprietary data for newsrooms, communications teams in corporations, all large organizations, and government communications teams.
My co-founder in The Rundown, Thomas Brasington, and I believe eventually you will have a RAG for your company, small or large. What it means is that you can essentially build Google on your own data. Think about that for a minute. You can create your own search engine, one that’s pretty good, and you do not need Google-type money to do it. In fact, there are free models kicking around already.
We are working on a communications advisor chatbot called Alisha and prototyping ideas for our modern communications academy.

therundown.studio
What communication problem are we solving?
The large language models out there today are powerful. Complex prompt engineering and fine tuning have made these models highly evolved, but they don’t have up-to-date data information, and they will make things up. RAG solves this by letting you provide accurate, up-to-date information and enforcing certain behaviours when there isn’t an answer. In some ways, it lets you build a Google-level search engine for your data.
If you have information that’s often requested—data, proposals, styles, basic facts, approved quotes—that you share frequently and a volume of in-house information that lives in a folder somewhere, Sharepoint, or a Google Drive, I want you to consider how a dedicated RAG can help you and your organization.
My observations working with various partners over the years
Over the years, I’ve worked with large health organizations, media companies, a large development network, the United Nations, and corporations, and I find I am often searching (and waiting) for information. Information that’s buried in internal systems, in emails, statistics no one can find, a document for a speech given a year ago, an impact report, whatever. If the stories, the messaging, the guidelines, the numbers, reports, etc. can be queried in a database, this solves a problem. It gives an answer accurately, immediately, and in natural language. RAG allows general AI to also cite sources, like a research paper.
How does a RAG work?
The idea of RAG works like this. There's no need to retrain the entire model (Bard, Chat GPT), you can simply add new content via a vector database to augment the existing information using embeddings. Vectors allow for similarity searches on content, making them great for broad questions in an AI chat.
Retrieval Augmented Generation means fetching up-to-date or context-specific data from an external database and making it available to an LLM when asking it to generate a response, solving this problem. You can store proprietary business data or information about the world and have your application fetch it for the LLM at generation time, reducing the likelihood of hallucinations. The result is a noticeable boost in the performance and accuracy of your GenAI application.
Practically, that would look like this:
- You take your data (which could be PDFs, Word documents, emails, Markdown files, or even a content management system) and pipe it through a series of scripts that will chunk it up into smaller pieces, convert the text into embeddings, and then store that data in your vector database.
- The user can now ask a question to your chat bot or dedicated search engine
- The question is converted into a set of vectors
- That query is matched against the vectors in your database for suitable matches (you can set how precise it has to be)
- IF there is a match, the relevant content is then returned to the AI model
- The AI model can then parse that content in response to the context of the question you asked and give you an answer that is accurate.
- Prompt engineering plays a part here, as you can either allow the AI model to only use the content or come up with an answer.
RAG passes additional relevant content from your domain-specific database to an LLM at generation time, alongside the original prompt or question, through a “context window". An LLM’s context window is its field of vision at a given moment. RAG is like holding up a cue card containing the critical points for your LLM to see, helping it produce more accurate responses incorporating essential data.
Our RAG: Wanja
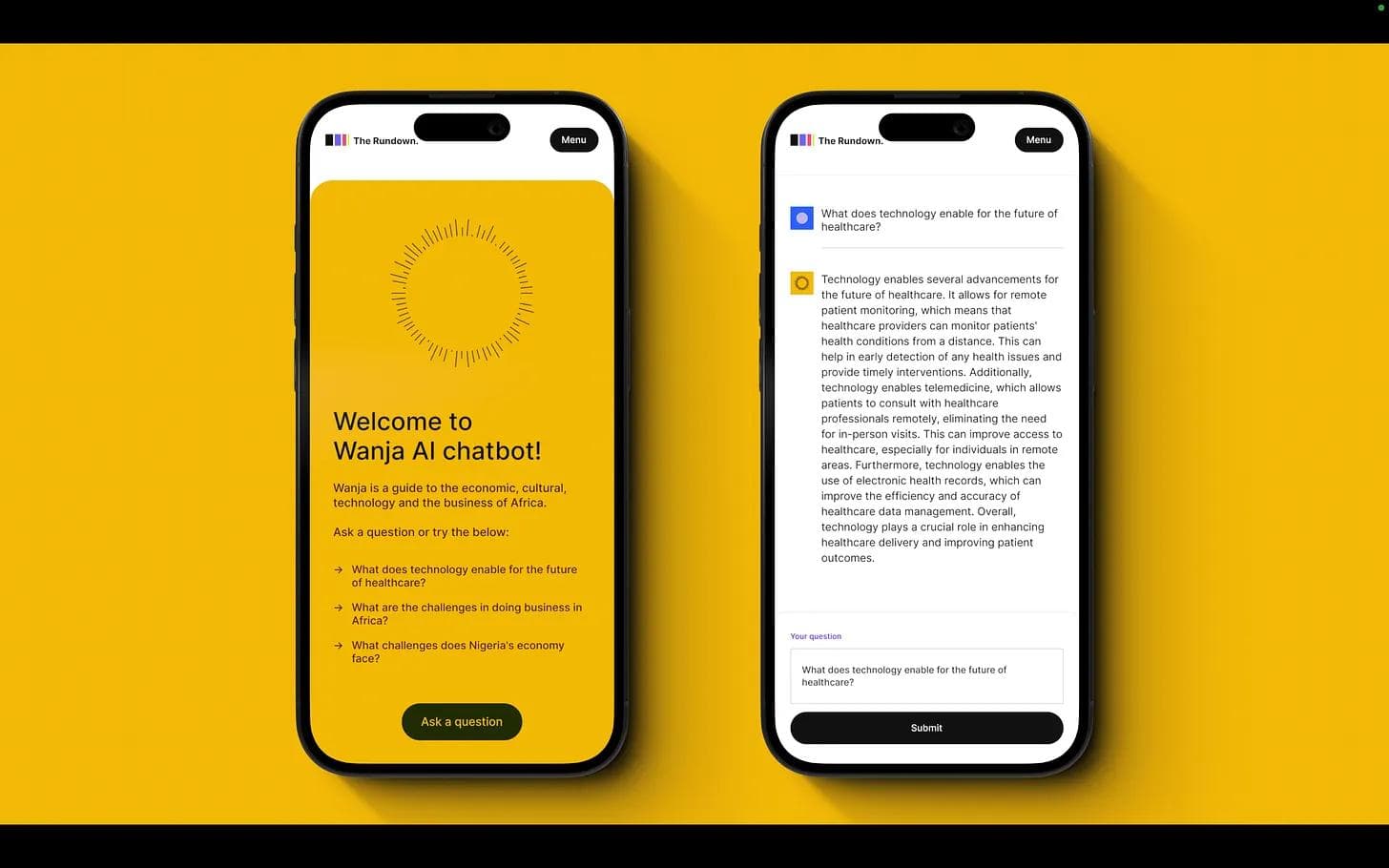
Our team at The Rundown is currently running a RAG by creating Wanja. She is your guide to understanding Africa and ultimately helping you with communications and information. We have taken data sets, credible interviews, and publicly available data on climate in Africa, creative and cultural industries, and how to do business in Africa. We have structured the data for all this.
We know that Google and Perplexity AI can get you information, but Wanja has credible information from our curated African sources. She is not perfect. You can access her today here. This showed us:
- If you have data sets that are large, insightful, or niche , creating a rag will be useful
- Communications teams in large organizations can build a RAG that gives them information about the organisation that’s approved, supports internal communications efforts, locates key stories and provides basic information journalists are looking for
- It’s a great way to open up and discover your data. You can ask broad questions about topics you think you have information on, and it can be used to expose the range of topics embedded within it.
Here’s how we built Wanja
We took all our documents and created five themes around which our guiding editorial ideas live. We broke them down into chunks of relevant information and put them under the themes we identified. This was important to prepare for data ingestion. This is known as structuring unstructured data. We generated our embeddings from this data and stored it in our vector database. The chunks of information we have broken down then became available for data query, retrieval, and synthesis. We are using OpenAI for embeddings and our LLM (but we could swap this out for any of the many models available today).

Wanja
Lessons Learned from Wanja
- Initially, we had large chunks of text, which meant that we weren’t getting great matches. To solve this, we introduced more headings in markdown with smaller paragraphs to get a higher, more accurate hit rate.
- Wanja would retrieve the first and last sentences and then forget the middle. so we were having a “lost in the middle” issue. low precision and “fluff”
- The prompt would sometimes be ignored, and if there was no content, Wanja would revert to the LLM and make up information. We found that moving to GPT-4 vs. GPT 3.5-turbo improved this, but the cost increase was significant.
- We are currently using simpler programming techniques to cut off the LLM if we don’t have relevant information.
- Knowing what to initially search for was a UX (user experience) challenge, so we have been experimenting with suggesting topics and follow-ups.
- We are looking at measuring the performance of Wanja and evaluating our RAG.
Applying this experience to thezvg.com and my professional client work
This experience is telling me that with any vast amount of information or knowledge base, all organizations and companies, large and small, can create dedicated RAGs to access information more efficiently. and boost team productivity and internal communications. Even as an individual, you can use this technology to build a “second brain.”. Check this out. And this. For more.
This technology lets you access knowledge in ways that have been difficult to achieve up until now.I do believe communications leaders of the future are going to be structuring teams totally differently, and newsrooms especially will need to be thinking fast about the skill sets required for success, trust, and new business models.
The Communications Future: A Perspective
If we were in charge of your company, we would be thinking
- Is there value in creating a RAG?
- Determine if it should be internal or external.
- Create a communications RAG unit and divide it in two parts: technical and editorial
- Have chunking teams trained up and RAG editors to fact-check
- Establish ethical policies
- Establish security process
- Determine where your RAG tool can be accessed (website, desktop app)
Interested to learn more?
Sign up today to get notified on the future of communication and AI
More from the blog
I Plan To Eliminate Myself From My Job. Let Me Explain.
My work is in the field of communications. A professional field where AI will transform (is transforming) this space super fast. Better, faster, and smarter tools will replace many of the tasks I do.
Creating an AI Partnership Powered by Ethics
It’s important that you are transparent about how the information you are submitting, publishing, or sharing was obtained. Have a tagline in mind so audiences are aware. Mine is: AI Sous-Chef.
My Top 10 List of the Best AI Teachers and Tools
I love lists. I love checklists. Here are some of the teachers, tips, and tools I use. I hope you find it helpful.
My Journey With Midjourney Version Six --V 6
I've had to relearn prompts for Midjourney. Less Words. More chatty. More direct. The bottom line is that it's significantly better. These images super realistic.